Google dremel: гипердвигатель аналитической обработки данных
")
Бизнес – штука жёсткая. И жёсткие требования зачастую предъявляет к времени получения информации.
О таких ситуациях говорят, что на вопрос, когда нужно представить данные, следует ответ: «Вчера».
В крупных компаниях подобных авральных сценариев – пруд пруди. А уж в таком информационном гиганте, как Google, «вчера»-запросов – целый океан.
«Через пятнадцать минут у нас видеоконференция с токийским филиалом. Подготовьте к ней данные по количеству обращений к рекламным объявлениям AdWords в Токио, Осаке и Киото за последние три дня».
«Как можно быстрее нарисуйте мне график тенденций трафика AdWords в регионе «Россия и страны СНГ» за первую декаду этого месяца».
Такие вот обращения на получение данных «здесь и сейчас» до недавнего времени были головной болью аналитиков Google. Базовым инструментом решения подобных задач агрегирования информации в структуре стека технологий Google является фреймворк MapReduce – система пакетной обработки запросов, совершенно не приспособленная к интерактивному времени отклика.
Чрезвычайно мощный инструмент обработки собранного поисковым гигантом веб-контента безбожно пасует перед решением класса задач OLAP (online analytical processing) – обработки данных в реальном масштабе времени.
Но, возможно, для такой обработки большой «момент силы» MapReduce и не нужен?
Так же, как не всегда в строительном деле нужен мощный перфоратор. Иногда проще обойтись простеньким, но оборотистым шуруповёртом.
Аналогия с электроинструментом не случайна. Google, разработав собственный вариант OLAP-системы, «заточенной» под особенности обрабатываемых сервисами компании массивов данных, назвала его Dremel.
Это название она позаимствовала у компании Dremel – лидера в производстве шустрых домашних электропомощников.
Разрыв шаблона для достижения скорости света
Результат работы Google Dremel поразителен даже для опытного специалиста по базам данных. За несколько десятков секунд система обрабатывает сотни миллиардов строк неиндексированных данных!
Это кажется невероятным даже в том случае, если учесть возможности распараллеливания обработки в кластере Google.
Каким же образом этот электронный аналитик так быстро агрегирует информацию?
Ответ кроется в происходящем из латыни термине in situ (буквально «на месте»), который отражает особенности алгоритма работы Dremel, основанного на выполнении операций агрегирования данных непосредственно в хранимом массиве. Проще говоря, Dremel использует алгоритм обработки данных, интегрированный в структуру обрабатываемых данных.
Эдакий электронный вариант ДНК. И в этом его коренное отличие от MapReduce, использующего информационный массив в качестве входного параметра.
MapReduce неспешно, шаг за шагом, тщательно «перемалывает» поступающие на его вход данные. В отличие от него, Dremel сам является частью структуры этих данных и способен получить искомую информацию «на месте» – in situ.
Чтобы добиться этого, инженерам и аналитикам Google пришлось «порвать шаблон» традиционного хранения информации и рассмотреть альтернативные варианты хранилищ, способные удовлетворить другим требования к оперативности работы.
Первым шагом на этом пути было понимание того факта, что большинство хранящихся в компании данных а) являются нереляционными и б) имеют вложенную (nested) структуру.
Веб-документы, исходные коды, протокольные сообщения, которыми обмениваются компоненты распределенных систем, файлы журналов сетевых служб. Вложенная структура этих данных заметно замедляет их анализ.
Ведь алгоритму агрегирования нужно не просто найти требуемую запись в Google Bigtable или Spanner и не только определиться с искомым столбцом в этой записи. В найденном столбце требуется углубиться в иерархию хранимых документов и при этом не ошибиться в определении, какому из уровней вложенности какое значение принадлежит.
А если учесть, что записи NoSQL и NewSQL хранилищ Google частенько являются сильно разреженными, то время выполнения этой трудоёмкой задачи возрастает в разы.
Но что если отказаться от хранения данных в виде записей? Что если значения одинаковых классов данных поместить в отдельные столбцы и работать только с ними?
Тогда для выборки данных не потребуется двухуровневая операция «поиск строки – поиск столбца в ней». Достаточно перейти к нужному столбцу и начать работу только с ним.
Идея хранилищ данных, ориентированных на столбцы (column-striped storage), – вовсе не ноу-хау инженеров Google. Первые работы в области таких моделей данных появились в середине восьмидесятых годов прошлого столетия и были связаны со всё той же необходимостью оперативного извлечения данных в активно развивающихся тогда системах логистики.
Идея хранения данных в виде столбцов появилась тридцать лет назад, но лишь теперь производители СУБД стали относиться к ней серьезно.
Специалисты Google не просто скопировали идею модели данных на основе столбцов. Они творчески переработали ее применительно к вложенной структуре подавляющего большинства своих информационных массивов.
В результате получилось хранилище нового типа – nested columnar storage, что в вольном переводе означает «хранилище вложенных данных на базе столбцов». Именно в его архитектуре и был заложен принцип in situ – та самая ДНК Dremel.
База столбцов групп вложенности и конечный автомат в одном флаконе
Проблема определения степени вложенности данных в основанном на столбцах хранилище только на первый взгляд кажется простой. Как определить, на каких уровнях хранимое значение повторялось, принадлежит ли оно двум и более записям или же появляется только в одной, но на разных уровнях вложенности?
И что делать с данными, которые на одном уровне вложенности документа определены полностью, а на другом частично отсутствуют?
Попытка разрешить эти вопросы привела исследователей Google к интересному решению. Что если внести небольшую избыточность в хранимые данные, добавив к ним дополнительную информацию о повторяемости значений и их наличии или отсутствии в исходном документе?
Так в каждом элементе столбца появились два дополнительных уровня: повторения (repetition) и определения (definition).
Поскольку большинство обрабатываемых сервисами Google документов имеют вложенную структуру, разработчикам Dremel пришлось серьёзно модифицировать модель column-striped-хранилища. Результатом явилась nested columnar storage – база столбцов групп вложенности документов.
Уровень повторения кодирует каждое появление значения в столбце на разных уровнях вложенности одного документа или их принадлежность другому документу. Фактически он представляет собой счётчик повторения значения в столбце, увеличивающийся по мере нахождения этого значения на более глубоких уровнях вложенности.
Благодаря этому исчезает необходимость многократного хранения одного и того же значения. Оно заменяется цепочкой чисел, указывающих на его упоминания на разных уровнях вложенности документа.
Уровень определения отвечает за устранение избыточности в тех случаях, когда значение на некотором уровне вложенности явно не определено. Например, для поля Language в структуре html-документа не указано конкретное значение языка по умолчанию.
Кроме того, уровень определения решает проблему разреженных данных – значений, частично отсутствующих на разных уровнях вложенности. Заменив их значением NULL с уровнем определения, равным 1, можно указать алгоритму агрегирования, что в этом месте документа информации нет.
Таким образом, кодирование документа любой сложности и с любым количеством уровней вложенности сводится к определению заголовков столбцов, в которых хранятся присваиваемые им значения, и вычислению значений уровней повторения и определения для каждого значения каждого столбца. Для экономии места сами данные сжимаются, а значения уровней повторения и определения сохраняются только в тех случаях, когда это действительно необходимо.
Ну а что же представляет собой этот самый алгоритм сборки исходного документа из совокупности столбцов? Поскольку в основе его функционирования лежит принцип in situ, то сама структура столбцов уже содержит алгоритм сборки.
Точнее говоря, он представлен конечным автоматом: его состояниями является множество столбцов, на которые был разделен документ, а переходами между ними – значения уровней повторения. Поскольку результат работы конечного автомата – его финальное состояние, то, задавая на множестве столбцов разные варианты состояний и переходов между ними, можно создать подмножество автоматов, каждый из которых агрегирует требуемую совокупность данных.
В Dremel не существует специально выделенных функций обработки данных. Сама структура данных определяет набор конечных автоматов ее обработки.
В этом и заключается принцип in situ – обработка «на месте» хранения данных.Дерево обслуживания Dremel. От корня к листьям
Принцип обработки хранимых данных in situ – только одна из причин высокой скорости обработки запросов Dremel. Другой её причиной является возможность поделить обработку входящих запросов между многочисленными узлами кластера Google.
Идея такого распараллеливания была позаимствована у распределённых поисковых систем (distributed search engine), основой которых является дерево обслуживания (serving tree) – многоуровневое распределение общей задачи поиска на подзадачи, упрощающиеся от вышележащих к нижележащим уровням обслуживания.
Дерево обслуживания Dremel состоит и корневого (root) сервера, получающего запросы на выборку и агрегацию данных. Эти запросы являются симбиозом языка SQL и шаблонов регулярных выражений.
Их интерпретация позволяет Dremel понять, каким из множества конечных автоматов оперировать для получения требуемых данных.
Следующим уровнем – «ветвями» дерева обслуживания Dremel – являются промежуточные серверы, хранящие автоматные модели выполнения запросов в виде внутреннего дерева их выполнения (query execution tree). «Листьями» же дерева обслуживания являются локальные хранилища – фактически чанк-серверы файловой системы GFS. Запросы пользователей, полученные root-сервером Dremel рассылаются промежуточным серверам, которые, обращаясь к легиону серверов-«листьев», реализуют на хранимых в них столбцах требуемые конечные автоматы агрегирования данных.
Архитектура сервиса Google Dremel основана на понятии «дерево обслуживания» (serving tree). Каждый ее уровень отвечает за свой участок работы.
Распараллеливание запроса на обработку идёт от «корня» дерева к его «листьям».
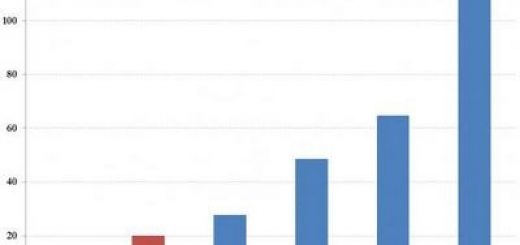
Проведённые при разработке Dremel сравнительные исследования производительности такой технологии на тестовых информационных массивах, состоящих из триллионов записей, показали, что для пакетного алгоритма MapReduce получение результата требовало десятков минут, в то время как in situ-алгоритм Dremel справлялся с той же задачей за секунды.
Сравнительная оценка производительности Dremel и MapReduce на одном и том же информационном массиве. Возможности Dremel позволяют агрегировать данные буквально в считанные секунды.
Как и большинство сервисов Google, прежде чем получить «путевку в жизнь» и стать сервисом общего назначения, Dremel более шести лет проходил обкатку в качестве внутреннего инструмента аналитиков, инженеров и программистов Google.
Лишь в 2012 году открылся основанный на Dremel инструментарий для разработчиков веб-сервисов, требующих интерактивной аналитической обработки данных под названием BigQuery. Благодаря продуманному набору функций программного интерфейса любой пользователь BigQuery может реализовать в своем приложении мгновенную выборку требуемых ему данных, либо используя для этого петабайтные информационные массивы поисковика номер один, либо разместив данные своей компании в арендуемом у Google облачном хранилище.
Пример SQL-запроса к BigQuery на подсчёт всех статей в Wikipedia, начинающихся с числовых значений (5-й президент США, 100 лучших писателей современности и т. д.). Результат обработки этого запроса получен за 9 секунд.
В любой ситуации Dremel гарантирует, что любой запрос будет выполнен за считанные секунды – те самые, счёт на которые порой определяет прогресс в любом бизнесе.
Dremel VS Китайский Dremel Часть 1